(**
// can't yet format YamlFrontmatter (["title: Parsing Motley Fool"; "category: Scripts"; "categoryindex: 2"; "index: 1"], Some { StartLine = 2 StartColumn = 0 EndLine = 6 EndColumn = 8 }) to pynb markdown
[](/ConferenceCalls//TranscriptParsing.fsx)
[](/ConferenceCalls//TranscriptParsing.ipynb)
# Transcript Parsing
The objective of this `TranscriptParsing.fsx` script is to give a few examples
on how to parse html documents with F#. More specifically, we will be attempting
to parse earnings call transcripts from [Motley Fool](https://www.fool.com).
Before getting started, lets download the [FSharp.Data](https://fsprojects.github.io/FSharp.Data/)
nuget package using .NET's package manager [NuGet](https://www.nuget.org/packages/FSharp.Data/):
*)
#r "nuget: FSharp.Data"
open System
open FSharp.Data
(**
## Transcript - Url
We can download or parse individual html documents with their url.
Since each call transcript will have a different url, we need
to find an effective and consistent way to fetch individual urls
from motley fool's website. Fortunately, if we take a look at motley fool's front page, we see that all call transcripts are tagged with hyperlinks.
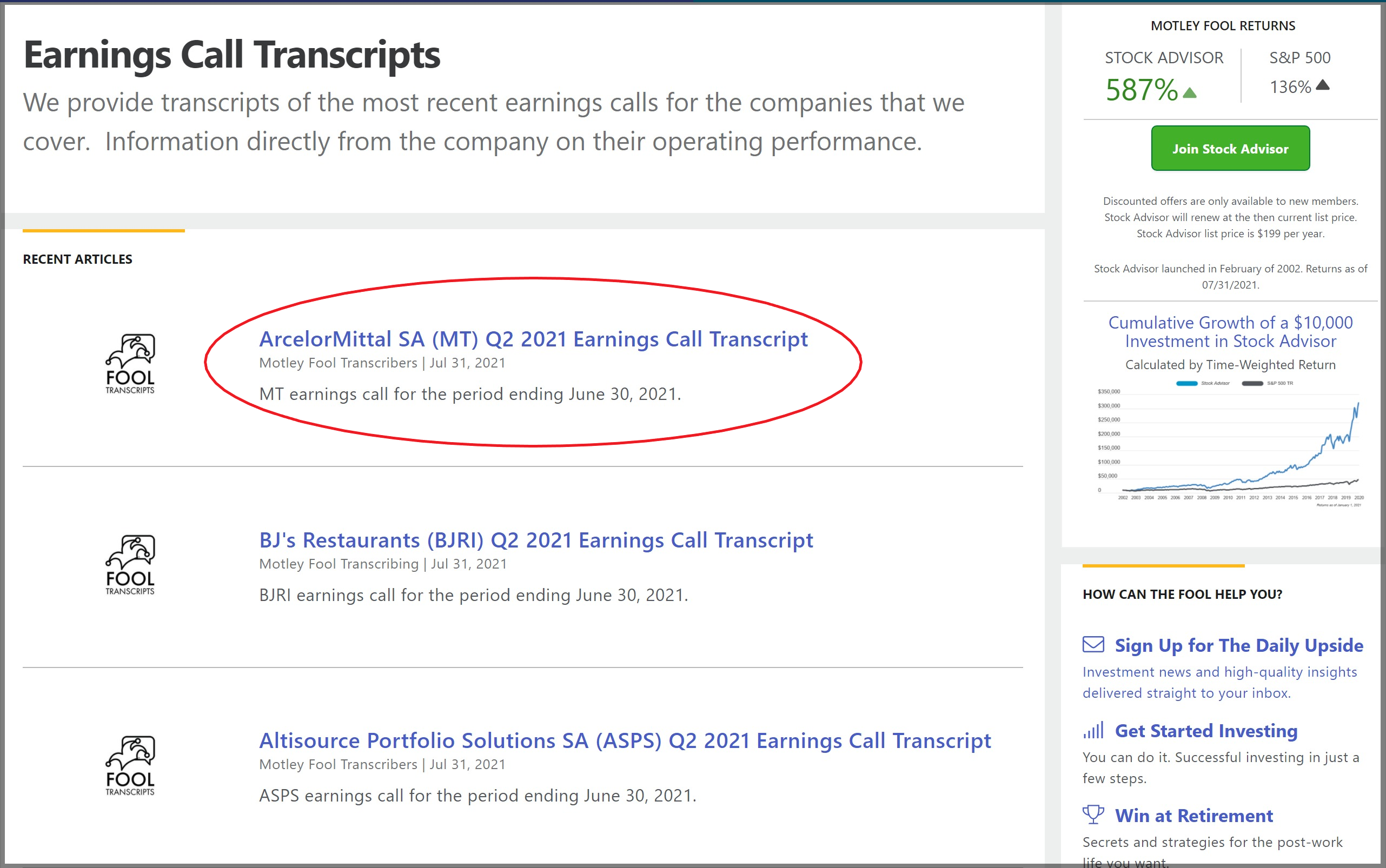 Since the transcripts are tagged with a specific hypertext reference
(href) (`"/earnings/call-transcripts"`), we can use the `CssSelect`
method from FSharp Data to find all elements in a given front page
that match the transcript href that we are looking for. After fetching
the urls, we can download any transcript we want as an html document
using the `HtmlDocument.Load` method, also from FSharp Data.
*)
type FrontPageDocument = HtmlDocument
/// Match html node with "href" attribute and create transcript url
let makeFoolUrl (attrib:HtmlAttribute) =
match attrib.Name(), attrib.Value() with
| "href", stub -> $"https://www.fool.com{stub}"
| _, _ -> failwithf $"Expected href attribute but got {attrib}"
/// Search for transcript urls
let findTranscriptUrls (pageDoc: FrontPageDocument): string [] =
pageDoc.CssSelect("a[href^='/earnings/call-transcripts']")
|> Seq.choose (HtmlNode.tryGetAttribute "href")
|> Seq.map makeFoolUrl
|> Seq.toArray
(**
Lets take a look at the first three call transcript urls `CssSelect` was able to match:
*)
let exampleFrontPageDoc: FrontPageDocument = HtmlDocument.Load "https://www.fool.com/earnings-call-transcripts/?page=1"
let exampleUrls = findTranscriptUrls exampleFrontPageDoc
/// First three urls
exampleUrls
|> Array.take 3
|> Array.iter (fun xs -> printfn$"{xs}")(* output:
val exampleFrontPageDoc : FrontPageDocument =
*)
(**
Although we are working with a small sample, we can already notice that
the time of the earnings calls are varied and that calls occur before
market hours, during market hours and even after market hours.
## Async methods
*)
let asyncTranscript (url: string) =
let rec loop attempt url =
async {
try
let! transcriptDoc = HtmlDocument.AsyncLoad url
let transcriptRec = parseTrancriptDoc transcriptDoc
return transcriptRec
with e ->
if attempt > 0 then
do! Async.Sleep 2000 // Wait 2 seconds in case we're throttled.
return! loop (attempt - 1) url
else return! failwithf "Failed to request '%s'. Error: %O" url e }
loop 5 url
let asyncPage (n: int) =
let rec loop attempt n =
async {
printfn $"{n}"
let frontPageP = $"https://www.fool.com/earnings-call-transcripts/?page={n}"
try
let! pageDoc = HtmlDocument.AsyncLoad frontPageP
return findTranscriptUrls pageDoc
with e ->
if attempt > 0 then
do! Async.Sleep 2000 // Wait 2 seconds in case we're throttled.
return! loop (attempt - 1) n
else return! failwithf "Failed to request '%s'. Error: %O" frontPageP e }
loop 5 n
(**
### Parse Transcript Pages
*)
module Async =
let ParallelThrottled xs = Async.Parallel(xs, 5)
let asyncPages (pages: int list) =
let urls =
pages
|> Seq.map asyncPage
|> Async.ParallelThrottled
|> Async.RunSynchronously
|> Array.collect id
let transcripts =
urls
|> Array.map asyncTranscript
|> Async.ParallelThrottled
|> Async.RunSynchronously
|> Array.choose id
transcripts
// Done
let examplePages = asyncPages [1 .. 5]
(**
## Export to json
*)
#r "nuget: Newtonsoft.Json"
open Newtonsoft.Json
Environment.CurrentDirectory <- __SOURCE_DIRECTORY__
let transcriptsToJson (fileName: string) (calls: EarningsCall []) =
JsonConvert.SerializeObject(calls)
|> fun json -> IO.File.WriteAllText(fileName, json)
transcriptsToJson "data-cache/examplePages.json" examplePages
Since the transcripts are tagged with a specific hypertext reference
(href) (`"/earnings/call-transcripts"`), we can use the `CssSelect`
method from FSharp Data to find all elements in a given front page
that match the transcript href that we are looking for. After fetching
the urls, we can download any transcript we want as an html document
using the `HtmlDocument.Load` method, also from FSharp Data.
*)
type FrontPageDocument = HtmlDocument
/// Match html node with "href" attribute and create transcript url
let makeFoolUrl (attrib:HtmlAttribute) =
match attrib.Name(), attrib.Value() with
| "href", stub -> $"https://www.fool.com{stub}"
| _, _ -> failwithf $"Expected href attribute but got {attrib}"
/// Search for transcript urls
let findTranscriptUrls (pageDoc: FrontPageDocument): string [] =
pageDoc.CssSelect("a[href^='/earnings/call-transcripts']")
|> Seq.choose (HtmlNode.tryGetAttribute "href")
|> Seq.map makeFoolUrl
|> Seq.toArray
(**
Lets take a look at the first three call transcript urls `CssSelect` was able to match:
*)
let exampleFrontPageDoc: FrontPageDocument = HtmlDocument.Load "https://www.fool.com/earnings-call-transcripts/?page=1"
let exampleUrls = findTranscriptUrls exampleFrontPageDoc
/// First three urls
exampleUrls
|> Array.take 3
|> Array.iter (fun xs -> printfn$"{xs}")(* output:
val exampleFrontPageDoc : FrontPageDocument =
*)
(**
Although we are working with a small sample, we can already notice that
the time of the earnings calls are varied and that calls occur before
market hours, during market hours and even after market hours.
## Async methods
*)
let asyncTranscript (url: string) =
let rec loop attempt url =
async {
try
let! transcriptDoc = HtmlDocument.AsyncLoad url
let transcriptRec = parseTrancriptDoc transcriptDoc
return transcriptRec
with e ->
if attempt > 0 then
do! Async.Sleep 2000 // Wait 2 seconds in case we're throttled.
return! loop (attempt - 1) url
else return! failwithf "Failed to request '%s'. Error: %O" url e }
loop 5 url
let asyncPage (n: int) =
let rec loop attempt n =
async {
printfn $"{n}"
let frontPageP = $"https://www.fool.com/earnings-call-transcripts/?page={n}"
try
let! pageDoc = HtmlDocument.AsyncLoad frontPageP
return findTranscriptUrls pageDoc
with e ->
if attempt > 0 then
do! Async.Sleep 2000 // Wait 2 seconds in case we're throttled.
return! loop (attempt - 1) n
else return! failwithf "Failed to request '%s'. Error: %O" frontPageP e }
loop 5 n
(**
### Parse Transcript Pages
*)
module Async =
let ParallelThrottled xs = Async.Parallel(xs, 5)
let asyncPages (pages: int list) =
let urls =
pages
|> Seq.map asyncPage
|> Async.ParallelThrottled
|> Async.RunSynchronously
|> Array.collect id
let transcripts =
urls
|> Array.map asyncTranscript
|> Async.ParallelThrottled
|> Async.RunSynchronously
|> Array.choose id
transcripts
// Done
let examplePages = asyncPages [1 .. 5]
(**
## Export to json
*)
#r "nuget: Newtonsoft.Json"
open Newtonsoft.Json
Environment.CurrentDirectory <- __SOURCE_DIRECTORY__
let transcriptsToJson (fileName: string) (calls: EarningsCall []) =
JsonConvert.SerializeObject(calls)
|> fun json -> IO.File.WriteAllText(fileName, json)
transcriptsToJson "data-cache/examplePages.json" examplePages